vol.46
- ChatGPT
- コツ・知識
- メールマガジン
【プロンプトあり】ChatGPTの活用事例をご紹介!
~Excel・Pythonでデータを分析しよう

(約5分で読めます)
~~~~~~~~~目次~~~~~~~~~
1.ChatGPTでできること(Excel・Python編)
■Excel
■Python
2.前回作成したダミーデータを前処理、分析、可視化しよう
(1)Excel
(2)Python
3.おわりに
~~~~~~~~~~~~~~~~~~~~
1. ChatGPTでできること(Excel・Python編)
前回はChatGPTを使って、「文章・画像・データ生成、企画」業務を楽にする方法について、お伝えしました。前回のブログ記事をご覧になりたい方・実際に試してみたい方は、以下のリンクからご確認くださいませ。【プロンプトあり】ChatGPTの活用事例をご紹介!~文章・画像生成から企画まで
今回はChatGPTを使って、ExcelとPythonの業務を効率化する方法についてご紹介します。
※今回はChatGPT4のみに質問をしています。データの読み込みは行えないものの、ChatGPT3.5でもプロンプト次第で同様の回答が返ってくるかと存じます。ぜひお試しくださいませ。
また以下に、ChatGPT3.5でExcelデータの整形を行えるプロンプトの作成方法を学べる研修をご紹介します。ぜひご覧くださいませ。
(半日研修)業務効率化のためのChatGPT活用研修
まずは、ChatGPTを使ってできることをご紹介します。
■Excel
・データ入力の自動化
・データ整形
・関数の作成
・データ分析
・VBA(マクロ)の作成
・データ格納用テンプレートの作成
■Python
・データの読み込み
・データの前処理
・データ分析
・データの書き出し
・データの可視化
・データベース操作
・自動化のコード生成
・APIの利用
上記は、ChatGPT4に効率化できる業務を聞いた回答です。私は関数やコードの生成で利用していましたが、どちらもデータ関連業務を多く効率化できそうでした。
2. 前回作成したダミーデータを前処理、分析、可視化しよう
前回、ChatGPTでの業務効率化についてご紹介した記事で、ダミーデータを作成しました。今回はそのダミーデータを利用して、データの前処理、分析、可視化を行ってみます。また上記を、より分析しがいのあるデータにするため、列(性別、年齢)と欠損値を追加しました。以下に作成したダミーデータとプロンプト文を記載しますので、ぜひご覧くださいませ。
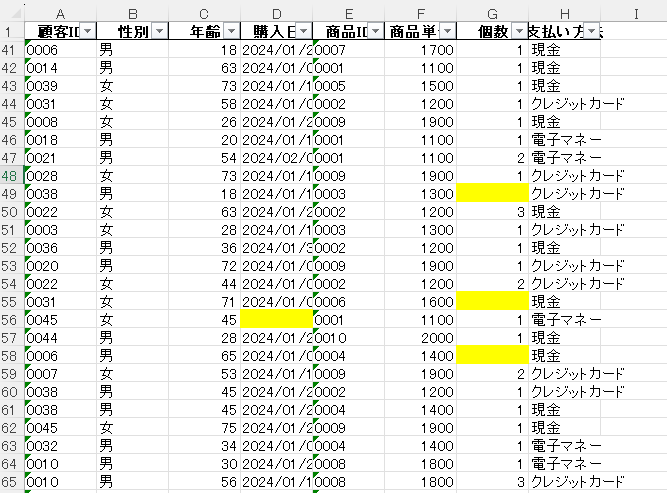
ダミーデータのダウンロード(クリックでダウンロードできます!)
※上記の画像では、欠損値の有無を分かりやすくするために一部の行を非表示、かつ欠損値に色を付けております。ダウンロードいただくデータに色はついておりませんので、ご留意くださいませ。
プロンプト文
(GPT4で前回作成したダミーデータを読み込ませました。)
・商品IDと費用が紐づくようにしてほしい(例:0001=1,100円のように)
・顧客IDの隣に性別(男か女)と年齢(18~75までの中でランダム)を追加してほしい
・性別と年齢は顧客IDに紐づくように設定してください
・データの前処理を行いたいため、欠損値などを入れてほしい
・欠損値は「個数」と「購入日」のみに設定してください
また、前回ダミーデータを作成した条件は以下の通りです。
#条件
・項目は「顧客ID、購入日、商品ID、商品単価、個数、支払い方法」
・100行のデータを出力する
・顧客IDは0001~0050の中でランダムに出力する(重複あり)
・商品IDは0001~0010の中でランダムに出力する(重複あり)
・購入日は2024/1/1~2024/2/1の中でランダムに出力する
・個数は1,2,3の中で7:2:1の割合でランダムに出力する
・金額は1,000~2,500の中で●,●00となるように出力する(重複あり)
・支払い方法は「現金、クレジットカード、電子マネー」のどれかをランダムに出力する
上記のデータを「dummy_data.xlsx」という名前でExcel形式で出力してください。
また、このダミーデータ作成に使われたコードを以下に記載します。
#コード
from datetime import datetime, timedelta
import random
import pandas as pd
# Set the seed for reproducibility
random.seed(0)
# Generate data
data = []
for _ in range(100):
customer_id = f"{random.randint(1, 50):04d}"
product_id = f"{random.randint(1, 10):04d}"
purchase_date = (datetime(2024, 1, 1) + timedelta(days=random.randint(0, 31))).strftime('%Y/%m/%d')
quantity_distribution = [1] * 7 + [2] * 2 + [3]
quantity = random.choice(quantity_distribution)
unit_price = random.randint(1, 25) * 100
payment_methods = ["現金", "クレジットカード", "電子マネー"]
payment_method = random.choice(payment_methods)
data.append([customer_id, purchase_date, product_id, unit_price, quantity, payment_method])
# Create DataFrame
columns = ["顧客ID", "購入日", "商品ID", "商品単価", "個数", "支払い方法"]
df = pd.DataFrame(data, columns=columns)
# Save to Excel
file_path = '/mnt/data/dummy_data.xlsx'
df.to_excel(file_path, index=False)
file_path
(1)Excel編
前処理:
プロンプト文(クリックで表示)
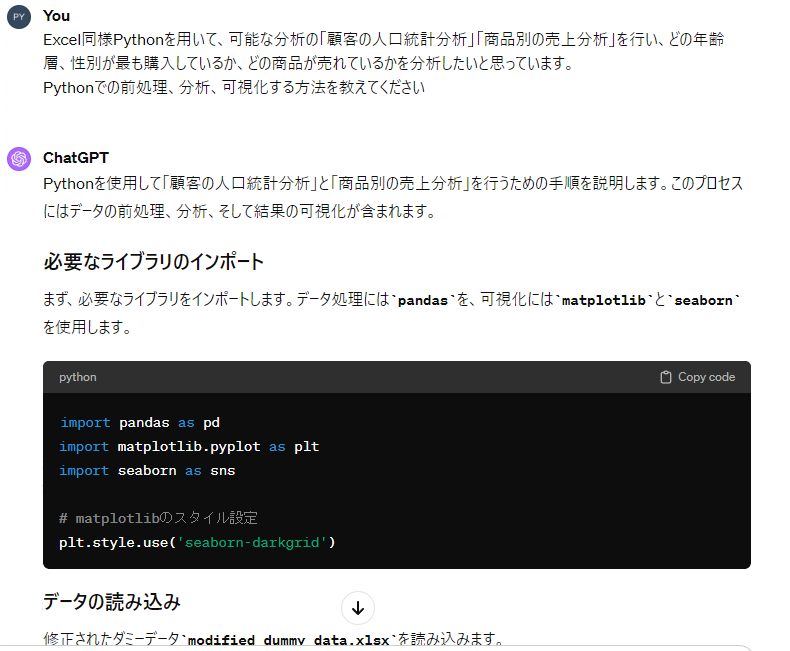
可能な分析の「顧客の人口統計分析」「商品別の売上分析」を行い、どの年齢層、性別が最も購入しているか、どの商品が売れているかを分析したいと思っています。
Excelを使って前処理、分析、可視化する方法を教えてください
②
前処理の方法をより具体的に教えてください。
回答(クリックで表示)
①の回答
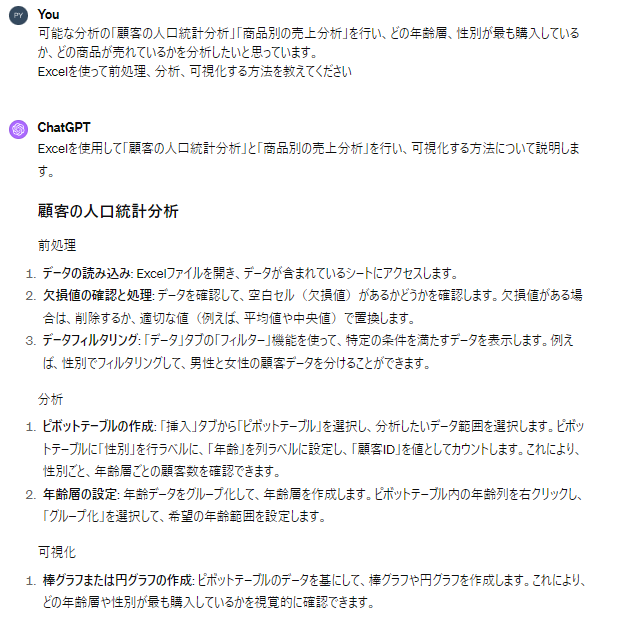

②の回答


実際に試してみた結果(クリックで表示)
欠損値の確認と処理
確認したところ、日付に2カ所、個数3箇所に欠損値が見つかりました。
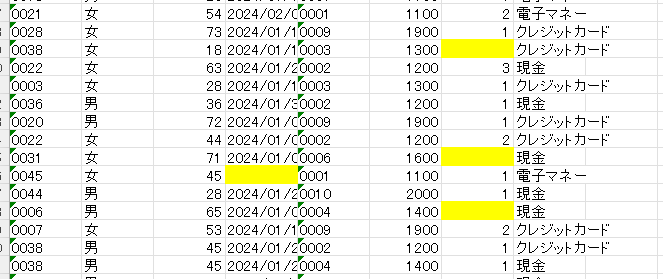
ChatGPTの回答をもとに、今回はすべての欠損値に1つ前のデータを入力しました。
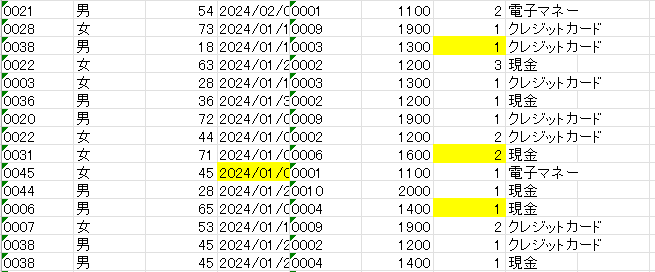
今回は比較的きれいなデータを使用しているため、前処理はこれで終了です。
次は分析に移ります。
分析:
プロンプト文(クリックで表示)
回答(クリックで表示)


実際に試してみた結果(クリックで表示)
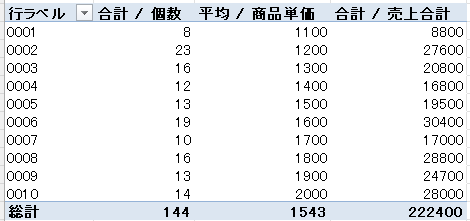
「顧客の人口統計分析」と「商品別の売上分析」の2つの側面からピボットテーブルを作成しました。ピボットテーブルには普段触らないのですが、ChatGPTに記載のように試し作成することができました。
顧客の人口統計分析

商品別の売上分析
可視化:
プロンプト文(クリックで表示)
回答(クリックで表示)


実際に試してみた結果(クリックで表示)
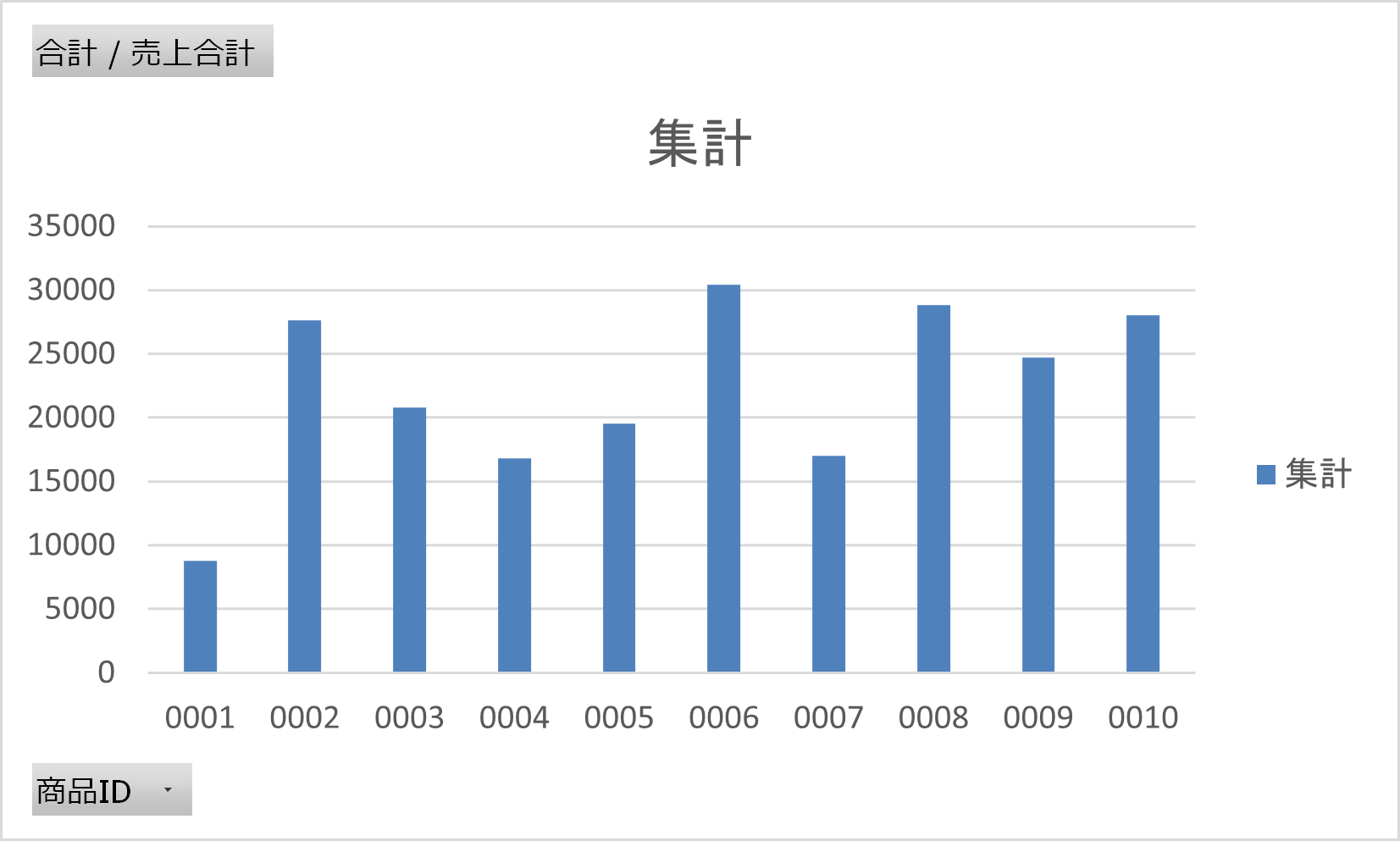
簡単にではありますが、グラフも作成できました。
顧客の人口統計分析の可視化
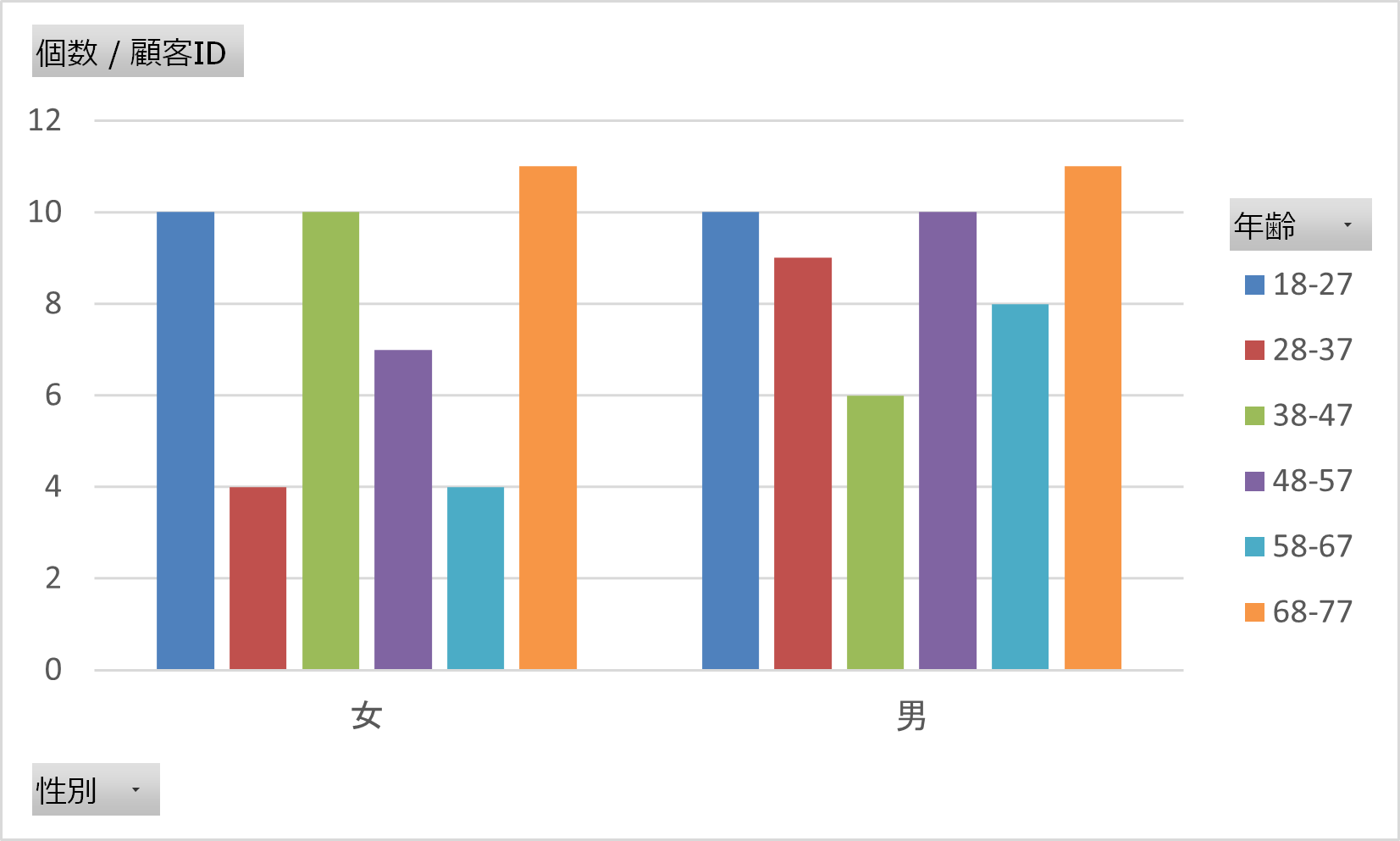
商品別の売上分析の可視化
「ChatGPTでExcelのマクロを作成し、業務を効率化する」という研修もございます。興味がございましたら、以下のリンクよりご確認くださいませ。
ChatGPT×Excel研修~知識ゼロからマクロを作る
(2)Python編
Pythonで質問をしたところ、Excelよりも的確に回答してもらえたため、回答(コード)はまとめて記載します。
①最初のプロンプト文と回答(クリックで表示)
最初のプロンプト文
回答(コード全文)
必要なライブラリのインポート
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# matplotlibのスタイル設定
plt.style.use('seaborn-darkgrid')
前処理
file_path = '/mnt/data/modified_dummy_data.xlsx' # 修正されたダミーデータのパス
df = pd.read_excel(file_path)
# 欠損値の処理
df.dropna(inplace=True) # 欠損値を含む行を削除
# データ型の変換(必要に応じて)
df['購入日'] = pd.to_datetime(df['購入日'])
分析
# 年齢層の定義
bins = [18, 30, 40, 50, 60, 70, 75]
labels = ['18-30', '31-40', '41-50', '51-60', '61-70', '71-75']
df['年齢層'] = pd.cut(df['年齢'], bins=bins, labels=labels, right=False)
# 性別と年齢層に基づく分析
demographic_analysis = df.groupby(['性別', '年齢層']).size().unstack(fill_value=0)
# 商品別の総売上計算
df['総売上'] = df['商品単価'] * df['個数']
sales_analysis = df.groupby('商品ID')['総売上'].sum()
可視化
demographic_analysis.plot(kind='bar', figsize=(10, 6), width=0.8)
plt.title('性別と年齢層に基づく購入行動')
plt.xlabel('性別と年齢層')
plt.ylabel('購入回数')
plt.xticks(rotation=45)
plt.show()
sales_analysis.plot(kind='bar', figsize=(10, 6), color='skyblue')
plt.title('商品別の総売上')
plt.xlabel('商品ID')
plt.ylabel('総売上')
plt.xticks(rotation=45)
plt.show()
②2回目のプロンプト文と回答(分析結果)(クリックで表示)
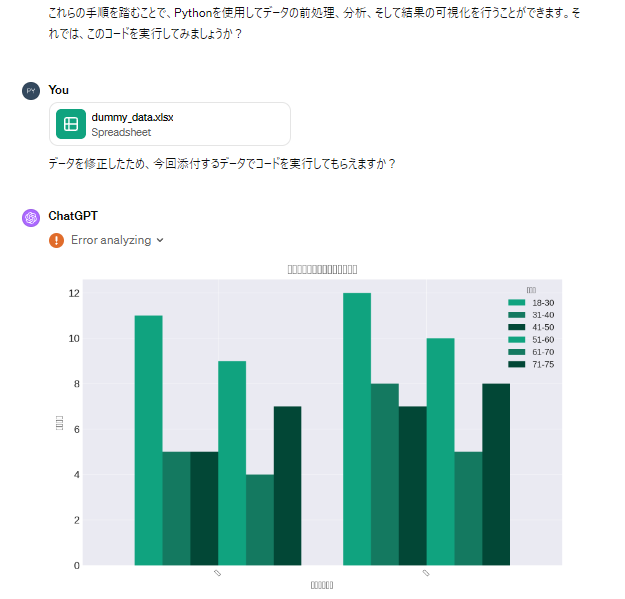
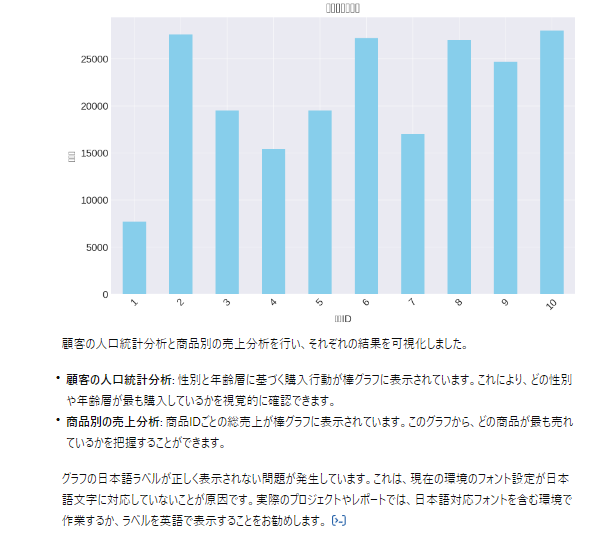
日本語のラベルが反映されないなど、一部修正が必要な箇所はあるものの、正確にグラフの作成までが完了しました。Pythonの場合はGPT4なら結果のみを出力することも可能でした。GPT3.5をご利用の場合は、上記に載せているコードをぜひお試しくださいませ。
「ChatGPTでPythonの業務を改善、効率化できる」研修も、現在多くの方にご受講いただいております。プログラミング経験はないが、プログラミングで業務の効率化を行いたい場合は、ぜひ以下のリンクからご確認くださいませ。
ChatGPT×Pythonプログラミング研修~自動化・データ分析編(5日間)
3. おわりに
今回は、ChatGPTを活用し、Excel・Pythonでデータを分析する方法についてご紹介しました!次回は今回に引き続き、Pythonを使ったデータ分析の方法をお伝えいたします。
様々なデータ分析用のライブラリも紹介いたしますので、次回もお読みいただけますと幸いです。

また今回は、「そら」というテーマでChatGPTを使用して画像を作成してみました。皆さんもぜひ色々な場面で活用してみてください。
最後までお読みいただき、ありがとうございました!
それでは、次回もお楽しみに!
著作権につきましては、AIによる生成ということで
議論がされている分野になりますので、商用利用などにつきましては
十分にご注意ください。
また、入力データは保持されませんが、回答データは保持されますので、
機密情報は入力しないようにご注意ください。



